

Au moment d’écrire cet article, cela fait six ans que j’ai décroché mon premier emploi en science des données. Et, pendant ces six années entières passées à faire de la science des données, Pandasa été le fondement de tout mon travail : analyses exploratoires de données, analyses d’impact, validations de données, expérimentation de modèles, etc. Ma carrière s’est construite là-dessus Pandas!
Inutile de dire que j’ai eu un sérieux Pandas blocage .
C’est-à-dire, jusqu’à ce que je découvre Polars, la nouvelle “bibliothèque DataFrame incroyablement rapide” pour Python.
Dans cet article, je vais vous expliquer :
- Qu’est-ce
Polarsque c’est, et qu’est-ce qui le rend si rapide ; - Les 3 raisons pour lesquelles je suis définitivement passé de
PandasàPolars;
– L’.arrespace de noms ;
–.scan_parquet()et.sink_parquet();
– Programmation orientée données.
Présentation de Polars : la bibliothèque de dataframes Python la plus rapide dont vous n’avez (peut-être) jamais entendu parler.
Peut-être en avez-vous entendu parler Polars, peut-être pas ! Quoi qu’il en soit, il prend lentement le dessus sur le paysage du traitement des données de Python, en commençant ici sur Towards Data Science :
- Leonie Monigatti a récemment écrit une comparaison temporelle complète de
PandasàPolars. - Wei-Meng Lee a déjà publié un guide de démarrage l’été dernier.
- Carl M. Kadie a écrit il y a quelques mois sur l’une des plus grandes différences au niveau de la surface entre
PandasetPolars–Polarsl’absence d’index .
Alors qu’est-ce qui rend Polarssi rapide ? À partir du PolarsGuide de l’utilisateur :
Polarsentièrement écritRust(pas de surcharge d’exécution !) et utiliseArrow– l’ implémentation native d’arrow2 – comme base… est écrit en Rust, ce qui lui donne des performances C/C++ et lui permet de contrôler entièrement les parties critiques des performances dans un moteur de requête… … Contrairement à des outils tels comme dask – qui essaie de paralléliser les bibliothèques monothread existantes comme NumPy et Pandas – Polars est écrit à partir de zéro, conçu pour la parallélisation des requêtes sur DataFramesRustPolars
Et voila. Polarsn’est pas seulement un cadre pour atténuer la nature monothread de Pandas, comme dask ou modin; il s’agit plutôt d’une refonte complète de la trame de données Python, y compris le format de mémoire en colonnes Apache Arrow hautement optimal comme base, et son propre moteur d’optimisation des requêtes pour démarrer. Et les résultats sur la vitesse sont époustouflants (selon le benchmark de données de h2oai ):
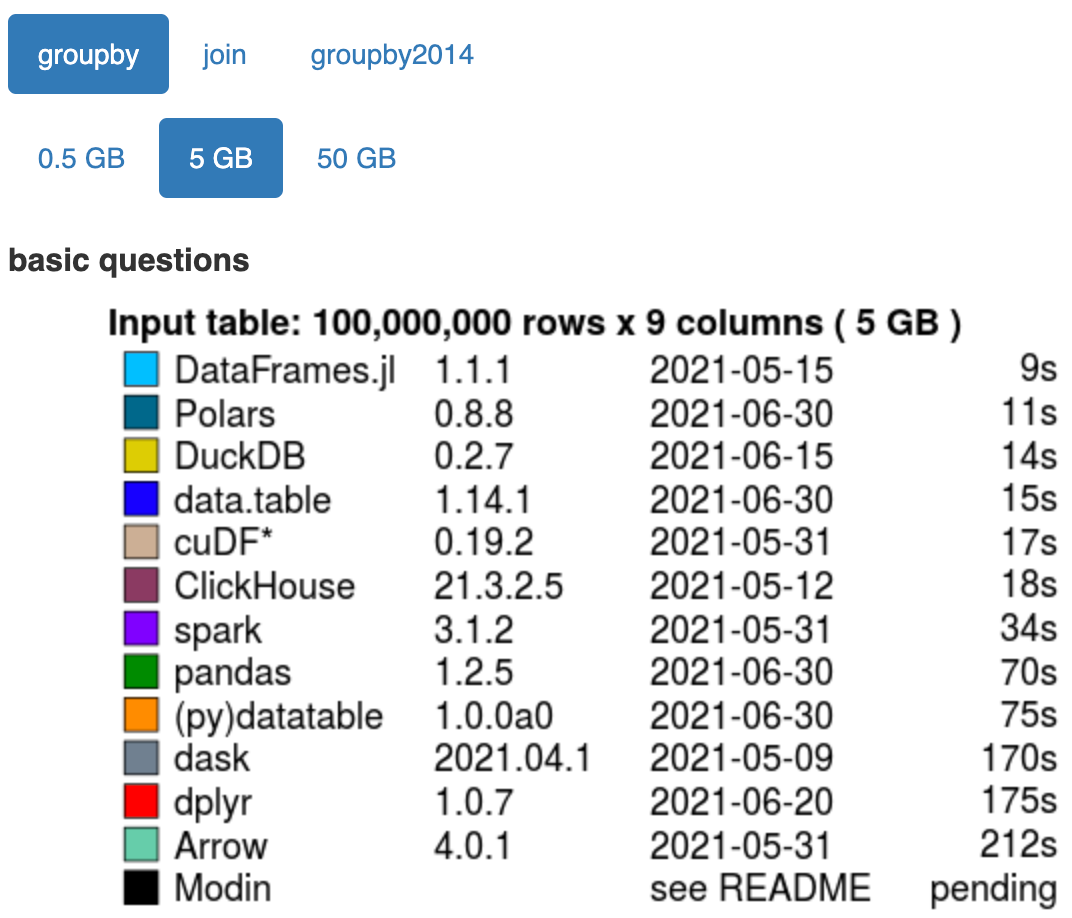
Sur une opération groupée d’une trame de données de 5 Go, Polarsest plus de 6 fois plus rapide que Pandas!
Cette vitesse à elle seule suffit à intéresser quiconque. Mais comme vous le verrez dans la suite de cet article, c’est la vitesse qui m’a intéressé, mais c’est vraiment la syntaxe qui m’a fait craquer.
Les 3 raisons pour lesquelles je suis définitivement passé des pandas aux polaires
1. L’ .arrespace de noms
Imaginez le scénario suivant dansPandas : vous disposez d’un ensemble de données de familles et d’informations les concernant, y compris une liste de tous les membres de la famille :
import pandas as pd
df = pd.DataFrame({
"last_name" : [ "Johnson" , "Jackson" , "Smithson" ],
"members" : [[ "John" , "Ron" , "Con" ], [ " Jack" , "Rack" ], [ "Smith" , "Pith" , "With" , "Lith" ]],
"city_of_residence" : [ "Boston" , "New York City" ,"Dallas" ]
})
imprimer (df)
>>>> nom_de_famille membres ville_de_résidence
0 Johnson [John, Ron, Con] Boston
1 Jackson [Jack, Rack] New York City
2 Smithson [Smith, Pith, With, Lith] Dallas
Pour votre analyse, vous souhaitez créer une nouvelle colonne à partir du premier élément de la membersliste. Comment est-ce que tu fais ça? Une recherche de l’ PandasAPI vous laissera perdu, mais une brève recherche de stackoverflow vous montrera la réponse !
La méthode dominante pour extraire un élément d’une liste dans une colonne Pandas est d’utiliser l’ .strespace de noms, comme ceci :
df[ "family_leader" ] = df[ "members" ]. str [ 0 ]
print (df)
>>>> nom_de_famille membres city_of_residence family_leader
0 Johnson [John, Ron, Con] Boston John
1 Jackson [Jack, Rack] New York City Jack
2 Smithson [Smith, Pith, With, Lith] Dallas Forgeron
Si vous êtes comme moi, vous vous demandez probablement « pourquoi dois-je utiliser l’ .strespace de noms pour gérer un listtype de données ? ».
Malheureusement, Pandasl’ .strespace de noms de ne peut pas effectuer toutes listles opérations souhaitées ; certaines choses nécessiteront un coûteux .applypar exemple. Dans Polars, cependant, ce n’est pas un problème. En se conformant au format de données en colonnes d’Apache Arrow, Polarsdispose de tous les types de données standard et des espaces de noms appropriés pour les gérer tous, y compris lists :
import polars as pl
df = pl.DataFrame({
"last_name" : [ "Johnson" , "Jackson" , "Smithson" ],
"members" : [[ "John" , "Ron" , "Con" ], [ " Jack" , "Rack" ], [ "Smith" , "Pith" , "With" , "Lith" ]],
"city_of_residence" : [ "Boston" , "New York City" ,"Dallas" ]
})
df = df.with_columns([
pl.col("membres" ).arr.get( 0 ).alias( "family_leader" )])
print (df)
>>>> ┌───────────┬───────── Ui ──────┐
│ nom_de_famille ┆ membres ┆ ville_de_résidence ┆ chef_de_famille │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ liste [ str ] ┆ str ┆ str │
╞══╕ ═══════╪═════════════════════════════╪════════════ ═══════╪═══════════════╡
│ Johnson ┆ [ "Jean" ,"Ron", "Con" ] ┆ Boston ┆ John │
│ Jackson ┆ [ "Jack" , "Rack" ] ┆ New York City ┆ Jack │ │
Smithson ┆ [ "Smith" , "Pith" , … "Lith" ] ┆ Dallas ┆ Smith │
└fiquement ─────────────┴───────────────┘
C’est vrai : Polarsest si explicite sur les types de données qu’il vous indique même le type de données de chaque colonne de votre dataframe à chaque fois que vous l’imprimez !
Cela ne s’arrête pas là cependant. Non seulement l’ PandasAPI nécessite l’utilisation de l’espace de noms d’un type de données pour la gestion d’un autre type de données, mais l’API est devenue tellement gonflée qu’il existe souvent de nombreuses façons de faire la même chose. Cela peut être déroutant, surtout pour les nouveaux arrivants. Considérez l’extrait de code suivant :
importer des pandas en tant que pd
df = pd.DataFrame({
"a" : [ 1 , 1 , 1 ],
"b" : [ 4 , 5 , 6 ]
})
column_name_indexer = [ "a" ]
boolean_mask_indexer = df[ "b" ]== 5
slice_indexer = tranche ( 1 , 3 )
pour o dans [column_name_indexer, boolean_mask_indexer, slice_indexer] :
print (df[o])
Dans cet extrait de code, la même Pandassyntaxe df[...]peut effectuer trois opérations distinctes : récupérer une colonne de la trame de données, effectuer un masque booléen basé sur les lignes sur la trame de données et récupérer une tranche de la trame de données par index.
Un autre exemple troublant est que, pour traiter dictdes colonnes avec Pandas, vous devez généralement exécuter une apply()fonction coûteuse ; Polars, d’autre part, a un structtype de données pour gérer dictdirectement les colonnes !
Dans Pandas, vous ne pouvez pas faire tout ce que vous voulez, et pour les choses que vous pouvez faire, il y a parfois plusieurs façons de les faire. Comparez cela avec Polars, où vous pouvez tout faire, les types de données sont clairs et il n’y a généralement qu’une seule façon de faire la même chose.
2. .scan_parquet()et.sink_parquet()
L’une des meilleures choses à propos Polarsest le fait qu’il offre deux API : une API impatiente et une API paresseuse.
L’API impatiente exécute toutes les commandes en mémoire, comme Pandas.
L’API paresseuse, cependant, ne fait tout que lorsqu’on lui demande explicitement une réponse (par exemple avec une .collect()instruction), un peu comme dask. Et, après avoir été invité à répondre, Polarss’appuiera sur son moteur d’optimisation des requêtes pour vous obtenir votre résultat dans les meilleurs délais.
Considérez l’extrait de code suivant, en comparant la syntaxe du Polarsimpatient DataFrameà celle de son homologue paresseux LazyFrame:
importer les polaires en tant que pl
impatient_df = pl.DataFrame({
"a" : [ 1 , 2 , 3 ],
"b" : [ 4 , 5 , 6 ]
})
lazy_df = pl.LazyFrame({
"a" : [ 1 , 2 , 3 ],
"b" : [ 4 , 5 , 6 ]
})
La syntaxe est remarquablement similaire ! En fait, la seule différence majeure entre l’API avide et l’API paresseuse réside dans la création, la lecture et l’écriture de trames de données, ce qui facilite le basculement entre les deux :

Et cela nous amène à .scan_parquet()et .sink_parquet().
En utilisant .scan_parquet()comme fonction d’entrée de données, LazyFramecomme cadre de données et .sink_parquet()comme fonction de sortie de données, vous pouvez traiter des ensembles de données plus volumineux que la mémoire ! C’est cool, surtout quand on le compare avec ce que le créateur de Pandaslui-même, Wes McKinney, a dit à propos Pandasde l’empreinte mémoire de dans un article intitulé « Apache Arrow et les « 10 choses que je déteste à propos des pandas » en 2017 :
“Ma règle d’or pour les pandas est que vous devriez avoir 5 à 10 fois plus de RAM que la taille de votre jeu de données”.
3. Programmation orientée données
Pandastraite les dataframes comme des objets, permettant la programmation orientée objet ; mais Polarstraite les dataframes comme des tables de données, permettant la programmation orientée données.
Laisse-moi expliquer.
Avec les dataframes, la plupart de ce que nous voulons faire est d’exécuter des requêtes ou des transformations ; nous voulons ajouter des colonnes, pivoter le long de deux variables, agréger, grouper par, vous l’appelez. Même lorsque nous voulons sous-ensembler un ensemble de données en train et tester pour former et évaluer un modèle d’apprentissage automatique, il s’agit par nature d’expressions de requête de type SQL.
Et c’est vrai — avec Pandas, vous pouvez effectuer la plupart des transformations, manipulations et requêtes sur vos données que vous souhaiteriez. Cependant, frustrant, certaines transformations et requêtes ne peuvent tout simplement pas être effectuées dans une expression, ou une requête si vous préférez. Contrairement à d’autres langages de requête et de traitement de données comme SQL ou Spark, de nombreuses requêtes nécessitent Pandasplusieurs expressions d’affectation successives et distinctes, ce qui peut compliquer les choses. Considérez l’extrait de code suivant, où nous créons une base de données de personnes et de leurs âges, et nous voulons voir combien de personnes il y a dans chaque décennie :
importer des pandas en tant que pd
df = (
pd.DataFrame({
"name" : [ "George" , "Polly" , "Golly" , "Dolly" ],
"age" : [ 3 , 4 , 13 , 44 ]
})
)
df[ "décennie" ] = (df[ "âge" ] / 10 ).astype( int ) * 10
décade_counts = (
df
.groupby( "décennie" )
[ "nom"]
.agg("count" )
)
print (decade_counts)
>>>> décennie
0 2
10 1
40 1
Il n’y a pas moyen de contourner cela – nous devons faire notre requête en trois expressions d’affectation. Pour le réduire à deux expressions, nous aurions pu utiliser l’ .assign()opérateur rarement vu à la place de l’ df["decade"] = ...opération, mais c’est tout ! Cela peut ne pas sembler être un gros problème ici, mais lorsque vous avez besoin de sept, huit, neuf expressions d’affectation successives pour faire le travail, les choses peuvent commencer à devenir un peu illisibles et difficiles à maintenir.
Dans Polars, cependant, cette requête peut être proprement écrite sous la forme d’une seule expression :
import polars as pl
decade_counts = (
pl.DataFrame({
"name" : [ "George" , "Polly" , "Golly" , "Dolly" ],
"age" : [ 3 , 4 , 13 , 44 ]
})
. with_columns([
((pl.col( "age" ) / 10 ).cast(pl.Int32) * 10 ).alias( "decade" )
])
.groupby( "decade" )
.agg(
pl.col( "nom").count().alias( "count" )
)
)
print (decade_counts)
>>>> ┌────────┬───────┐
│ décennie ┆ compte │
│ --- ┆ --- │
│ i32 ┆ u32 │
╞════════╪═══════╡
│ 0 ┆ 2 │
│ 10 ┆ 1 │
│ 40 ┆ 1 │
└fique ─┴───────┘
Si doux.
Vous pourriez lire tout cela et vous dire « pourquoi est-ce que je veux tout faire en une seule expression ? ». C’est vrai, peut-être pas. Après tout, de nombreux pipelines de données utilisent des requêtes intermédiaires, enregistrent les résultats intermédiaires dans des tables et interrogent ces tables intermédiaires pour obtenir le résultat final, voire pour surveiller la qualité des données.
Mais, comme SQL, Spark ou d’autres Pandaslangages non informatiques, Polarsvous donne 100% de flexibilité pour décomposer votre requête où vous le souhaitez afin de maximiser la lisibilité, tout en Pandasvous obligeant à décomposer votre requête en fonction des limitations de son API. C’est une aubaine non seulement pour la lisibilité du code, mais aussi pour la facilité de développement !
De plus, en prime, si vous utilisez l’API paresseuse avec Polars, vous pouvez diviser votre requête où vous voulez, en autant de parties que vous le souhaitez, et le tout sera de toute façon optimisé en une seule requête sous le capot.
Conclusion
Ce dont j’ai parlé dans cet article n’est qu’un aperçu de la supériorité de Polarsover Pandas; il reste encore de nombreuses fonctions dans Polarscette écoute de SQL, Spark et d’autres langages de traitement de données (par exemple pipe(), when(), et filter(), pour n’en nommer que quelques-uns).
Et même si Polarsc’est maintenant ma bibliothèque de référence pour le traitement et l’analyse de données en Python, je l’utilise toujours Pandaspour des cas d’utilisation étroits comme le style des cadres de données pour l’affichage dans des rapports et des présentations ou la communication avec des feuilles de calcul. Cela dit, je m’attends Polarsà comprendre Pandaspetit à petit au fil du temps.
Et ensuite ?
Démarrer avec un nouvel outil est difficile ; surtout s’il s’agit d’une nouvelle bibliothèque de dataframes, quelque chose qui est si essentiel à notre travail de data scientists ! Je peux fortement le recommander – il couvre toutes les bases de Polars, et m’a aidé à rendre la transition assez facile (je ne reçois aucun bonus de parrainage en suggérant ce cours ; je l’ai tout simplement tellement aimé !). Et cela m’amène à mon dernier point…