
Ces dernières années, le Deep Learning a fait des progrès remarquables dans le domaine du TAL.
Les séries temporelles, également de nature séquentielle, soulèvent la question : que se passe-t-il si nous apportons toute la puissance des transformateurs pré-entraînés à la prévision des séries temporelles ?
Cependant, certains articles, tels que [2] et [3] ont examiné les modèles d’apprentissage en profondeur. Ces documents ne présentent pas l’image complète. Même pour les cas NLP, certaines personnes attribuent la percée des modèles GPT à « plus de données et de puissance de calcul » au lieu de « meilleure recherche ML ».
Cet article vise à dissiper la confusion et à fournir une vision impartiale, en utilisant des données et des sources fiables provenant à la fois du milieu universitaire et de l’industrie. Plus précisément, nous couvrirons :
- Les avantages et les inconvénients du Deep Learning et des modèles statistiques .
- Quand utiliser des modèles statistiques et quand Deep Learning.
- Comment aborder un cas de prévision.
- Comment gagner du temps et de l’argent en sélectionnant le meilleur modèle pour votre cas et votre ensemble de données.
Plongeons dedans.
Les compétitions Makridakis sont une série de défis à grande échelle qui démontrent les dernières avancées en matière de prévision de séries chronologiques.
Récemment, Makridakis et publié un nouvel article qui :
- Résume l’état actuel des prévisions des 5 premières compétitions M.
- Fournit une référence complète de divers modèles de prévision statistiques, d’apprentissage automatique et d’apprentissage en profondeur.
Remarque : Nous aborderons les limites du document plus loin dans cet article.
Configuration de référence
Traditionnellement, Makridakis et ses associés publient un article résumant les résultats du dernier concours M.
Pour la première fois, cependant, les auteurs ont inclus des modèles de Deep Learning dans leurs expériences. Pourquoi?
Contrairement au NLP, ce n’est qu’en 2018-2019 que les premiers modèles de prévision DL ont été suffisamment matures pour défier les modèles de prévision traditionnels. En effet, lors du concours M4 en 2018, les modèles ML/DL se sont classés derniers.

Voyons maintenant les modèles DL/ML qui ont été utilisés dans le nouvel article :
- Perceptron multicouche (MLP) : Notre réseau de rétroaction familier.
- WaveNet : un réseau de neurones autorégressif qui combine des couches convolutives (2016).
- Transformer : Le Transformer original, introduit en 2017.
- DeepAR : le premier réseau auto-régressif réussi d’Amazon qui combine les LSTM (2017)
Remarque : Les modèles d’apprentissage en profondeur ne sont plus SOTA (état de l’art) (plus à cela plus tard). De plus, MLP est considéré comme un ML et non comme un modèle “profond”.
Les modèles statistiques de référence sont ARIMA et ETS (Exponential Smoothing) – des modèles bien connus et éprouvés.
De plus:
- Les modèles ML/DL ont d’abord été affinés grâce à un réglage hyper-paramètre.
- Les modèles statistiques sont entraînés série par série . Inversement, les modèles DL sont globaux (un seul modèle entraîné sur toutes les séries temporelles du jeu de données). Par conséquent, ils profitent de l’apprentissage croisé .
- Les auteurs ont utilisé l’assemblage : un modèle Ensemble-DL a été créé à partir de modèles de Deep Learning, et un Ensemble-S, composé de modèles statistiques. La méthode d’assemblage était la médiane des prévisions.
- L’ Ensemble-DL se compose de 200 modèles, avec 50 modèles de chaque catégorie : DeepAR, Transformer, WaveNet et MLP.
- L’étude a utilisé l’ensemble de données M3 : d’abord, les auteurs ont testé 1 045 séries chronologiques, puis l’ensemble de données complet (3 003 séries).
- Les auteurs ont mesuré la précision des prévisions à l’aide de MASE ( Mean Absolute Scaled Error ) et SMAPE ( Mean Absolute Percentage Error ). Ces métriques d’erreur sont couramment utilisées dans les prévisions.
Ensuite, nous fournissons un résumé des résultats et des conclusions obtenus à partir du benchmark.
1. Les modèles d’apprentissage en profondeur sont meilleurs
Les auteurs concluent qu’en moyenne, les modèles DL sont plus performants que les modèles statistiques. Le résultat est illustré à la figure 2 :

Le modèle Ensemble-DL surpasse clairement l’ Ensemble-S. De plus, DeepAR obtient des résultats très similaires avec Ensemble-S.
Fait intéressant, la figure 2 montre que bien qu’Ensemble-DL surpasse Ensemble-S, seul DeepAR bat les modèles statistiques individuels. Pourquoi donc?
Nous répondrons à cette question plus loin dans l’article.
2. Mais les modèles d’apprentissage en profondeur coûtent cher
Les modèles de Deep Learning nécessitent beaucoup de temps pour s’entraîner (et d’argent). C’est prévu. Les résultats sont présentés dans la figure 3 :

La différence de calcul est importante.
Par conséquent , réduire l’erreur de prévision de 10 % nécessite un temps de calcul supplémentaire d’environ 15 jours ( Ensemble-DL ). Bien que ce nombre semble énorme, il y a certaines choses à considérer :
- Les auteurs ne précisent pas quel type de matériel ils ont utilisé.
- Ils ne mentionnent pas non plus si une parallélisation ou une optimisation de la formation est utilisée.
- Le temps de calcul d’ Ensemble-DL peut être considérablement réduit si moins de modèles sont utilisés dans l’ensemble. Ceci est affiché dans la figure 4 :

J’ai mentionné précédemment que le modèle Ensemble-DL est un ensemble de 200 modèles DL.
La figure 4 montre que 75 modèles peuvent atteindre une précision comparable à 200 modèles avec seulement un tiers du coût de calcul. Ce nombre peut être encore réduit si une méthode plus intelligente pour faire l’ensemble est utilisée.
Enfin, le présent article n’explore pas les capacités d’apprentissage par transfert des modèles d’apprentissage en profondeur. Nous en discuterons également plus tard.
3. L’assemblage est tout ce dont vous avez besoin
Le pouvoir de l’assemblage est incontestable ( Figure 2 , Figure 3 ).
Ensemble -DL et Ensemble-SL sont les modèles les plus performants. L’idée est que chaque modèle individuel excelle à capturer différentes dynamiques temporelles. La combinaison de leurs prédictions permet l’identification de modèles complexes et une extrapolation précise.
4. Prévisions à court terme ou à long terme
Les auteurs ont cherché à savoir s’il existait une différence dans la capacité des modèles à prévoir à court terme par rapport à long terme.
Il y avait en effet.
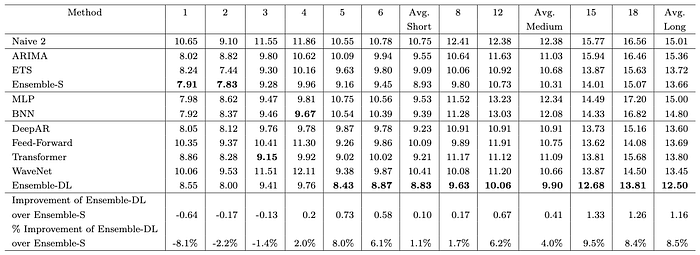
La figure 5 décompose la précision de chaque modèle pour chaque horizon de prévision. Par exemple, la colonne 1 affiche l’erreur de prévision d’un pas en avant. De même, la colonne 18 affiche l’erreur de la 18e prévision anticipée.
Il y a 3 observations clés ici :
- Premièrement, les prévisions à long terme sont moins précises que celles à court terme (pas de surprise ici).
- Dans les 4 premiers horizons, les modèles statistiques gagnent. Au-delà de cela, les modèles de Deep Learning commencent à s’améliorer et Ensemble-DL gagne.
- Plus précisément, dans le premier horizon, Ensemble-S est 8,1 % plus précis. Cependant, dans le dernier horizon, Ensemble-DL est 8,5% plus précis.
Si vous pensez à cela, cela a du sens:
- Les modèles statistiques sont auto-régressifs. Plus les horizons de prévision augmentent, plus les erreurs s’accumulent.
- En revanche, les modèles d’apprentissage en profondeur sont des modèles à sorties multiples. Par conséquent, leurs erreurs de prévision sont réparties sur toute la séquence de prédiction.
- Le seul modèle autorégressif DL est DeepAR. C’est pourquoi DeepAR fonctionne très bien dans les premiers horizons contrairement aux autres modèles DL.
5. Les modèles d’apprentissage en profondeur s’améliorent-ils avec plus de données ?
Dans l’expérience précédente, les auteurs n’ont utilisé que 1 045 séries chronologiques de l’ensemble de données M3.
Ensuite, les auteurs ont réexécuté leur expérience en utilisant l’ensemble de données complet (3 003 séries). Ils ont également analysé les prévisions de pertes par horizon. Les résultats sont présentés dans la figure 6 :

Maintenant, l’écart entre Ensemble-DL et Ensemble-S s’est rétréci. Les modèles statistiques correspondaient aux modèles d’apprentissage en profondeur dans le premier horizon, mais après cela, l’Ensemble-DL les a surpassés.
Analysons plus en détail les différences entre Ensemble-DL et Ensemble-S :

Au fur et à mesure que le pas de prédiction augmente, les modèles de Deep Learning surpassent l’ensemble statistique.
6. Analyse des tendances et de la saisonnalité
Enfin, les auteurs étudient comment les modèles statistiques et DL gèrent les caractéristiques importantes des séries chronologiques telles que la tendance et la saisonnalité.
Pour y parvenir, les auteurs ont utilisé la méthodologie de [5]. Plus précisément, ils ont ajusté un modèle de régression linéaire multiple qui a corrélé l’erreur sMAPE avec 5 caractéristiques clés de la série chronologique : possibilité de prévision ( caractère aléatoire des erreurs ) , tendance , saisonnalité , linéarité et stabilité ( transformation optimale des paramètres de Box-Cox qui détermine la normalité des données ) . Les résultats sont présentés dans la Figure 8 :

Nous observons que :
- Les modèles DL fonctionnent mieux avec des données bruyantes, à tendance et non linéaires .
- Les modèles statistiques sont plus appropriés pour les données saisonnières et à faible variance avec des relations linéaires.
Ces informations sont inestimables.
Par conséquent, il est crucial de procéder à une analyse approfondie des données exploratoires (EDA) et de comprendre la nature des données avant de sélectionner le modèle approprié pour votre cas d’utilisation.
Limites de l’étude
Cet article est sans aucun doute l’une des meilleures études sur l’état actuel du paysage de la prévision des séries chronologiques, mais il présente certaines limites. Examinons-les :
Absence d’algorithmes ML : Trees / Boosted Trees
La famille des modèles Boosted Trees occupe une place importante dans les problèmes de prévision de séries temporelles.
Les plus populaires sont XGBoost, LightGBM et CatBoost. De plus, LightGBM a remporté le concours M5.
Ces modèles excellent avec des données de type tabulaire. En fait, à ce jour, les arbres boostés sont le meilleur choix pour les données tabulaires. Cependant, l’ensemble de données M3 utilisé dans cette étude est simple car il contient principalement des séries univariées.
Dans une étude future, ce serait une bonne idée d’ajouter des arbres boostés à l’ensemble de données, en particulier pour les ensembles de données plus complexes.
Choisir M3 comme ensemble de données de référence
Le professeur Rob Hyndman, rédacteur en chef de la revue IJF, a déclaré : « L’ensemble de données M3 est utilisé depuis 2000 pour tester les méthodes de prévision ; les méthodes nouvellement proposées doivent battre M3 pour être publiées dans la FIJ. ”
Cependant, selon les normes modernes, l’ensemble de données M3 est considéré comme petit et simple, et n’est donc pas représentatif des applications de prévision modernes et des scénarios pratiques.
Bien sûr, le choix de l’ensemble de données ne diminue pas la valeur de l’étude. Néanmoins, la réalisation d’un futur benchmark avec un ensemble de données plus important pourrait fournir des informations précieuses.
Les modèles de Deep Learning ne sont pas SOTA
Maintenant, il est temps de s’adresser à l’éléphant dans la pièce.
Les modèles de Deep Learning de l’étude sont loin d’être à la pointe de la technologie.
L’étude a identifié DeepAR d’Amazon comme le meilleur modèle DL en termes de précision théorique des prévisions. C’est pourquoi DeepAR était le seul modèle capable de surpasser les modèles statistiques au niveau individuel. Cependant, le modèle DeepAR a maintenant plus de 6 ans.
Amazon a depuis publié sa version améliorée de DeepAR, appelée Deep GPVAR . En fait, Deep GPVAR est également obsolète – le dernier modèle de prévision Deep d’Amazon est le MQTransformer, qui a été publié en 2020.
De plus, d’autres modèles puissants comme Temporal Fusion Transformer (TFT) et N-BEATS (qui a récemment été surpassé par N-HITS) ne sont pas non plus utilisés dans l’ensemble Deep Learning.
Par conséquent, les modèles d’apprentissage en profondeur utilisés dans l’étude ont au moins deux générations de retard sur l’état actuel de la technique. Sans aucun doute, la génération actuelle de modèles de prévision profonde aurait produit de bien meilleurs résultats.
La prévision n’est pas tout
La précision est essentielle dans les prévisions, mais ce n’est pas le seul facteur important. Les autres domaines critiques sont :
- Quantification de l’incertitude
- Interprétabilité des prévisions
- Apprentissage Zero-Shot / Méta-apprentissage
- Ségrégation par changement de régime
En parlant de Zero-Shot Learning, c’est l’un des domaines les plus prometteurs de l’IA.
L’apprentissage zéro coup est la capacité d’un modèle à estimer correctement des données invisibles, sans être spécifiquement formé sur celles-ci. Cette méthode d’apprentissage reflète mieux la perception humaine.
Tous les modèles de Deep Learning, y compris les modèles GPT, sont basés sur ce principe.
Les premiers modèles de prévision bien connus qui tirent parti de ce principe sont N-BEATS / N-HITS . Ces modèles peuvent être formés sur un vaste ensemble de données de séries chronologiques et produire des prévisions sur des données complètement nouvelles avec une précision similaire à celle si les modèles avaient été explicitement formés sur eux.
L’apprentissage zéro coup n’est qu’un exemple spécifique de méta-apprentissage . De nouveaux progrès avec le méta-apprentissage sur les séries chronologiques ont été réalisés depuis. Prenez le concours M6 par exemple, dont le but était de trouver si la prévision et l’économétrie de la science des données peuvent être utilisées pour battre le marché, comme le font des investisseurs légendaires (par exemple Warren Buffet). La solution gagnante était une nouvelle architecture qui utilisait, entre autres, les réseaux de neurones et le méta-apprentissage .
Malheureusement, cette étude n’explore pas l’avantage concurrentiel des modèles d’apprentissage en profondeur dans une configuration d’apprentissage zéro coup.
L’étude de Nixtla
Nixtla, une start-up prometteuse dans le domaine de la prévision de séries chronologiques, a récemment publié un suivi de référence de Makridakis et al. papier [4].
Plus précisément, l’équipe Nixtla a ajouté 2 modèles supplémentaires : Complex Exponential Smoothing et Dynamic Optimized Theta .
L’ajout de ces modèles a réduit l’écart entre les modèles statistiques et d’apprentissage en profondeur. De plus, l’équipe de Nixtla a correctement souligné la différence significative de coût et de ressources nécessaires entre les deux catégories.
En effet, de nombreux scientifiques des données sont induits en erreur par les promesses surfaites du Deep Learning et n’ont pas la bonne approche pour résoudre un problème de prévision.
Nous en discuterons plus en détail dans la section suivante. Mais avant cela, nous devons répondre aux critiques auxquelles le Deep Learning est confronté.
Apprentissage en profondeur sous le feu
Les progrès du Deep Learning au cours de la dernière décennie sont phénoménaux. Et il n’y a pas encore de signe de ralentissement.
Cependant, chaque percée révolutionnaire qui menace de changer le statu quo est souvent accueillie avec scepticisme et critique. Prenez GPT-4 par exemple : ce nouveau développement menace 20 % des emplois américains au cours de la prochaine décennie [6].
La domination du Deep Learning et des Transformers dans le domaine du TAL est indéniable. Et pourtant, les personnes interrogées posent des questions qui ressemblent à ceci :
Les progrès de la PNL sont-ils attribués à une meilleure recherche, ou simplement à la disponibilité de plus de données et à une puissance informatique accrue ?
Dans les prévisions de séries chronologiques, les choses sont pires. Pour en comprendre la raison, vous devez d’abord comprendre comment les problèmes de prévision étaient traditionnellement abordés.
Avant l’adoption généralisée du ML/DL, la prévision consistait à créer les bonnes transformations pour votre ensemble de données. Cela impliquait de rendre la série chronologique stationnaire, de supprimer les tendances et les saisonnalités, de tenir compte de la volatilité et d’utiliser des techniques telles que les transformations de box-cox, entre autres. Toutes ces approches ont nécessité une intervention manuelle et une compréhension approfondie des mathématiques et des séries chronologiques.
Avec l’avènement du ML, les algorithmes de séries chronologiques sont devenus plus automatisés. Vous pouvez facilement les appliquer à des problèmes de séries chronologiques avec peu ou pas de prétraitement en dehors du nettoyage (bien qu’un prétraitement supplémentaire et une ingénierie des fonctionnalités soient toujours utiles). De nos jours, une grande partie de l’effort d’amélioration d’un tel projet se limite au réglage des hyperparamètres.
Par conséquent, les personnes qui ont utilisé des mathématiques et des statistiques avancées ne peuvent pas saisir le fait qu’un algorithme ML/DL peut surpasser un modèle statistique traditionnel. Et le plus drôle, c’est que les chercheurs n’ont aucune idée de comment et pourquoi certains concepts DL fonctionnent vraiment.
Prévision de séries chronologiques dans la littérature récente
Autant que je sache, la littérature actuelle manque de preuves suffisantes pour illustrer les avantages et les inconvénients des différentes catégories de modèles de prévision. Les 2 articles ci-dessous sont les plus pertinents :
Les transformateurs sont-ils efficaces pour la prévision de séries chronologiques ?
Un article intéressant [2] montre les faiblesses de certains modèles de prévision Transformers. L’article explique par exemple comment les schémas de codage positionnel, utilisés dans les modèles Transformer modernes, ne parviennent pas à capturer la dynamique temporelle des séquences temporelles. C’est vrai — l’auto-attention est invariante par permutation . Cependant, le document omet de mentionner les modèles Transformer qui ont effectivement résolu ce problème.
Par exemple, le Temporal Fusion Transformer (TFT) de Google utilise une couche LSTM d’encodeur-décodeur pour créer des incorporations sensibles au temps et au contexte. En outre, TFT utilise un nouveau mécanisme d’attention, adapté aux problèmes de séries chronologiques pour capturer la dynamique temporelle et fournir une interprétabilité.
De même, MQTransformer d’Amazon utilise son nouveau schéma d’encodage positionnel ( encodage de saisonnalité dépendant du contexte ) et son mécanisme d’attention ( attention sensible au retour d’informations ) .
Avons-nous vraiment besoin de modèles DL pour la prévision de séries chronologiques ?
Cet article [3] est également intéressant car il compare diverses méthodes de prévision dans les catégories statistiques , Boosted Trees , ML et DL .
Malheureusement, il est en deçà de son titre, car le meilleur modèle parmi les 12 modèles est le TFT de Google, un pur modèle de Deep Learning. Le journal mentionne :
… Les résultats du tableau 5 ci-dessus soulignent la compétitivité du GBRT configuré pour les prévisions glissantes, mais montrent également que des modèles basés sur des transformateurs considérablement plus puissants, tels que le TFT [12], surpassent à juste titre les performances de l’arbre de régression boosté.
En général, soyez prudent lorsque vous lisez des documents et des modèles de prévision sophistiqués, en particulier en ce qui concerne la source de publication. L’ International Journal of Forecasting (IJF) est un exemple de revue réputée axée sur les prévisions.
Comment aborder un problème de prévision
Ce n’est pas simple. Chaque ensemble de données est unique et les objectifs de chaque projet varient, ce qui rend les prévisions difficiles.
Néanmoins, cet article offre des conseils généraux qui peuvent être bénéfiques pour la plupart des approches.
Comme vous l’avez appris dans cet article, les modèles de Deep Learning sont une tendance émergente dans les projets de prévision, mais ils en sont encore à leurs débuts. Malgré leur potentiel, ils peuvent aussi être un piège.
Il n’est pas recommandé de prioriser immédiatement les modèles de Deep Learning pour votre projet. Selon Makridakis et al. et les études de Nixtla, il est préférable de commencer par des modèles statistiques. Un ensemble de 3 à 4 modèles statistiques peut être plus puissant que prévu. Essayez également les arbres boostés, surtout si vous avez des données tabulaires. Pour les petits ensembles de données (de l’ordre de milliers), ces méthodes peuvent être adéquates.
Les modèles d’apprentissage en profondeur peuvent fournir une amélioration supplémentaire de la précision de 3 à 10 %. Cependant, la formation de ces modèles peut être longue et coûteuse. Pour certains domaines, tels que la finance et la vente au détail, cette amélioration supplémentaire de la précision peut être plus bénéfique et justifier l’utilisation d’un modèle DL. Une prévision plus précise des ventes de produits ou du cours de clôture d’un ETF pourrait se traduire par des milliers de dollars de revenus supplémentaires.
D’autre part, les modèles DL comme N-BEATS et N-HITS ont des capacités d’apprentissage par transfert.
Si un ensemble de données de séries chronologiques suffisamment grand est construit et qu’une entité consentante pré-entraîne ces 2 modèles et partage leurs paramètres, nous pourrions facilement utiliser ces modèles et obtenir une précision de prévision de premier ordre (ou effectuer un petit réglage fin de notre ensemble de données d’abord).
Mot de la fin
La prévision de séries chronologiques est un domaine clé de la science des données.
Mais c’est aussi très sous-évalué par rapport à d’autres domaines. Les Makridakis et al. document[4] a fourni des informations précieuses pour l’avenir, mais il reste encore beaucoup de travail et de recherche à faire.
De plus, les modèles DL de prévision sont largement inexplorés.
Par exemple, les architectures Multi-Modales en Deep-Leaning sont partout. Ces architectures exploitent plus d’un domaine pour apprendre une tâche spécifique. Par exemple, CLIP (utilisé par DALLE-2 et Stable Diffusion ) combine le traitement du langage naturel et la vision par ordinateur .
L’ensemble de données de référence M3 ne contient que 3 003 séries chronologiques, chacune ne comportant pas plus de 500 observations. En revanche, le modèle de prévision Deep GPVAR réussi consiste en une moyenne de 44K paramètres. En comparaison, la plus petite version du modèle de transformateur de langage LLaMA de Facebook compte 7 milliards de paramètres et a été entraînée sur 1 000 milliards de jetons.
Donc, en ce qui concerne la question initiale, il n’y a pas de réponse définitive quant au modèle qui est le meilleur puisque chaque modèle a ses propres avantages et inconvénients.
Au lieu de cela, cet article vise à fournir toutes les informations nécessaires pour vous aider à sélectionner le modèle le plus adapté à votre projet ou cas.